Research
Uncertainty, sloppiness, and model reliability
Scientific and machine-learning models are increasingly used to interpret data, make predictions, and guide decisions in settings where experiments are expensive or incomplete. In these cases, prediction accuracy alone is not enough; we also need to understand when predictions are reliable, when they are uncertain, and when they should be treated with caution. Uncertainty quantification provides a principled framework for studying how uncertainties in data, model parameters, model structure, and assumptions propagate to final predictions.
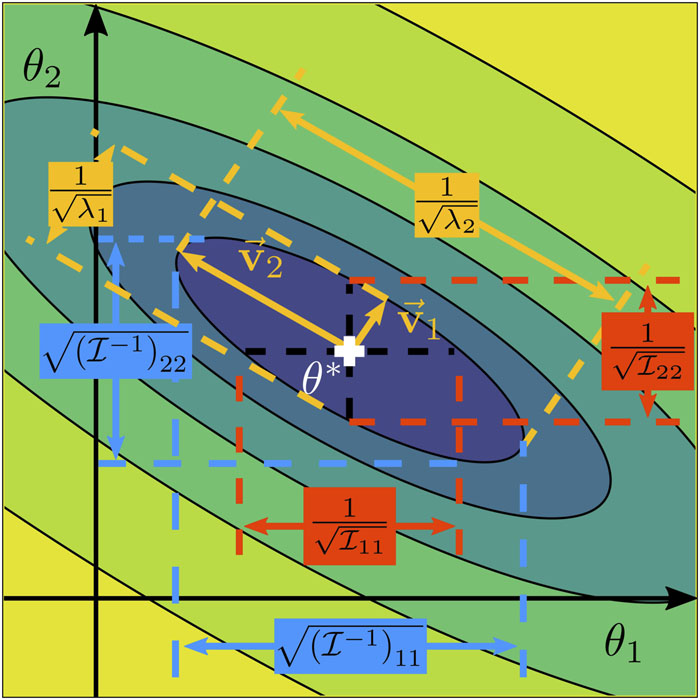
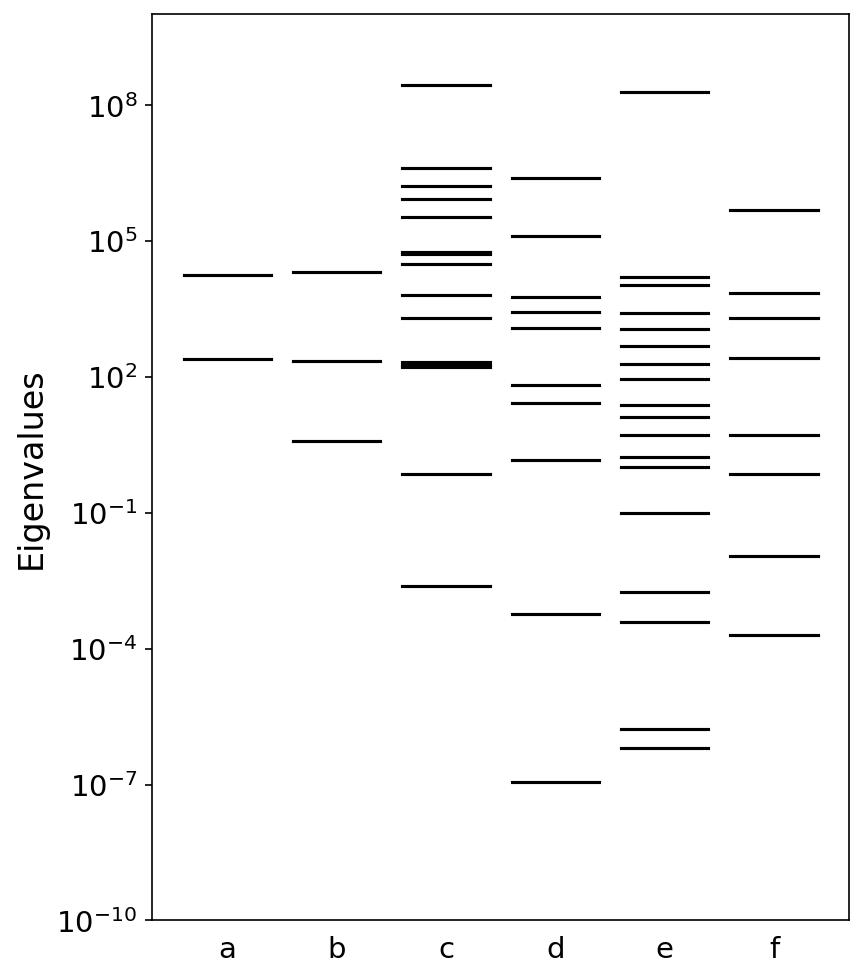
A recurring challenge in scientific modeling is that many models are sloppy: only a few combinations of parameters are tightly constrained by data, while many others remain weakly identifiable. The Fisher Information Matrix (FIM) provides a useful geometric tool for analyzing this structure by revealing which parameter directions are sensitive and which remain effectively unconstrained. My research uses this perspective and beyond to understand how uncertainty affects model predictions, which uncertainties matter most for scientific decisions, and how model reliability can be assessed in complex systems.
Active learning and information-matching
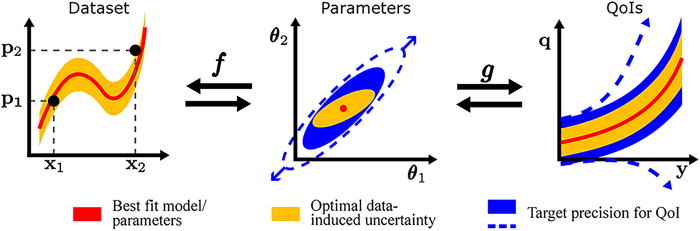
Even in the era of big data, high-quality scientific data remain expensive. Active learning (AL) aims to address this challenge by identifying which experiments, simulations, or measurements would be most informative. Many AL strategies seek to reduce global uncertainty, either in model parameters or in model predictions. However, this can be inefficient for scientific models with sloppy or unidentifiable parameters, where substantial effort may be spent reducing uncertainty in directions that have little effect on the quantities that ultimately matter.
Information matching (IM) takes a more targeted perspective: instead of trying to reduce uncertainty everywhere, the goal is to acquire enough information to make specific quantities of interest sufficiently precise. This reframes AL around decision-relevant predictions rather than global parameter precision. Because the framework is based on matching experimental information to the sensitivities of target predictions, it can be applied across a wide range of scientific and engineering problems, including atomistic-scale modeling and interatomic potentials, power network grids, underwater acoustics, electrochemical impedance spectroscopy, and other systems where data are costly and model predictions must be trusted. By linking experimental design to the geometry of parameter space and to the sensitivities of downstream predictions, information matching provides a principled and computationally efficient approach to data acquisition under uncertainty.
Reinforcement learning for scientific model generation

In recent work, I have explored how reinforcement learning can be used to automate scientific model construction, with a focus on electrochemical impedance spectroscopy (EIS). EIS is widely used to study electrochemical systems, but interpreting EIS data often requires selecting an appropriate equivalent circuit model, a process that can involve substantial expert judgment, manual trial-and-error, and ambiguity because different circuit structures may produce similar impedance responses.
We formulate equivalent circuit model generation as a sequential decision-making problem, where a reinforcement learning agent iteratively modifies a circuit topology and receives feedback based on fit quality and model complexity. The agent does not need to be given the ground-truth circuit structure; instead, it learns to construct candidate models directly from EIS data through reward feedback. The goal is not to replace scientific interpretation, but to accelerate model exploration, suggest useful candidate circuits, and support more systematic analysis of electrochemical measurements.